在树莓派3B上搭建Hass.io并接入米家和iOS(二)
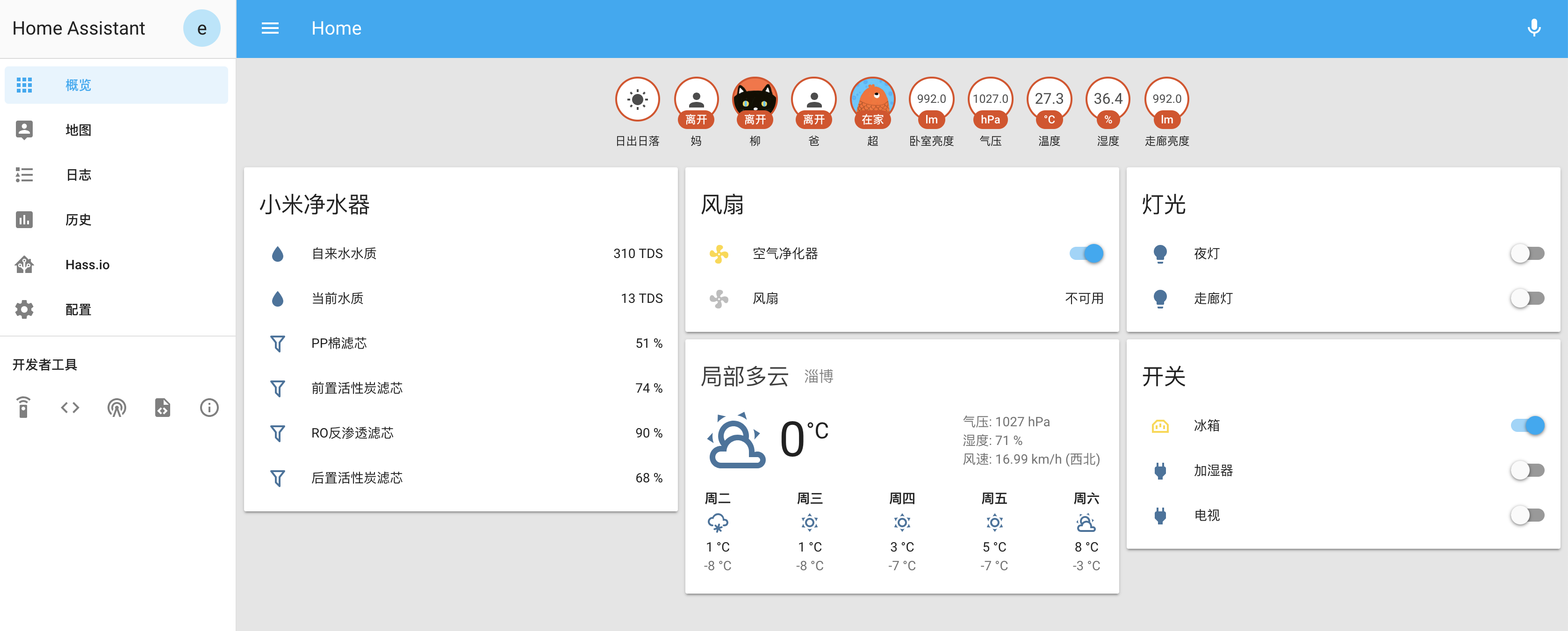
这是这个系列的第二篇,主要讲一下各种设备接入配置。先放一张目前我已经配置好的管理界面图片
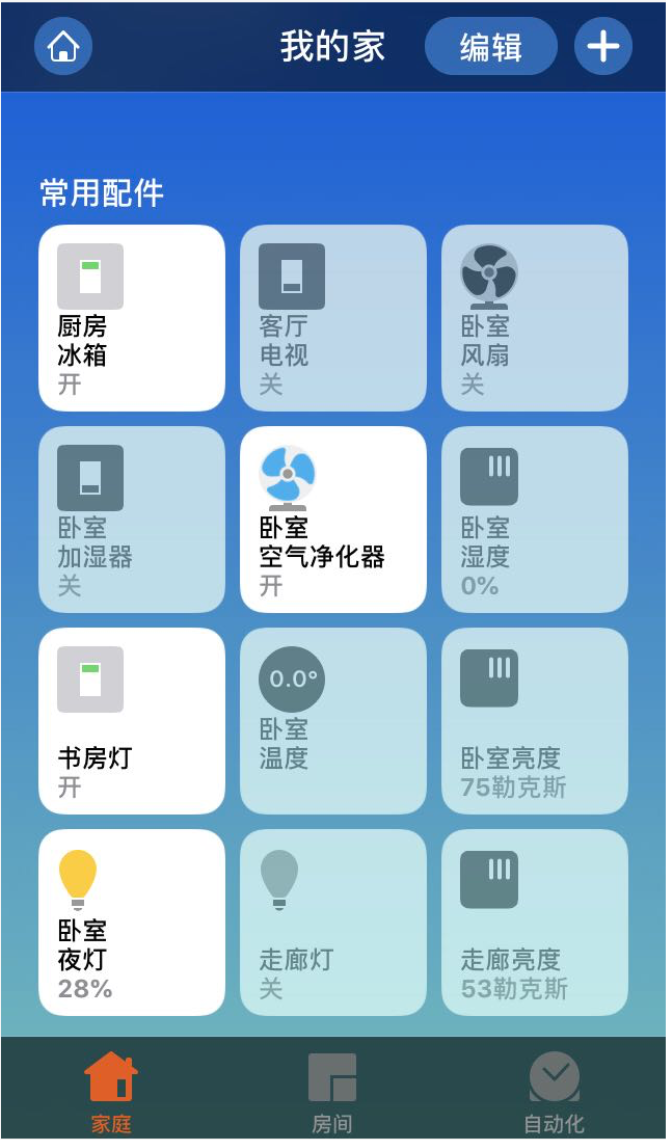
再放一张配置好的 HomeKit 截图
开始这篇之前,首先你要确保你已经安装了上一篇中提到的 SSH & Web Terminal 插件。
如何修改配置文件
如果已经安装好了 SSH & Web Terminal 插件并启动了,那么直接在 Terminal 中执行下面的命令就可以连接到树莓派上了。
1 | ssh [email protected] |
连接后 ,用 ls 查看目录

各个目录的作用如下:
- addons 存储自定义插件
- backup 备份目录
- config 配置文件目录已经自定义组件
- share 共享目录
- ssl 证书目录
我们配置的时候,主要就是修改 config 目录下的 configuration.yaml 文件。每次修改保存后,要先在后台的“配置”=>“通用”中“检查配置”,配置检查通过后,再重载配置或者重启服务(有些配置的修改需要重启服务才能生效)。
接入小米多功能网关
打开 config/configuration.yaml,加入下面的配置(根据你的情况选择是多网关还是单网关配置):
1 | # 使用单网关前提下,可不填 mac, mac 不带冒号 |
其中 key 的获取,需要打开米家App,打开网关页面,点击右上角的三个点,打开菜单后,选择“关于”,之后“玩法教程”下面的空白处点击5次,就会出现新的列表选项,点击“局域网通信协议”,里面的密码就是 key 了,另外要把最上面的那个“局域网通信协议”的开关打开。
保存重启,接入网关成功后,通过网关接入的各种 ZigBee 设备都会被 HomeAssistant 识别出来。
目前的支持情况参见这里:https://home-assistant.cc/component/xiaomi/zigbee/
接入小米Wifi设备
插座类的配置如下:
1 | switch: |
其中 name 可以自定义,host 是插座的IP地址,token则是通信用的凭证。
小米Wifi设备由于各个生产厂商的原因,并不像智能网关那么人性给提供设备的 token。获取 wifi 设备的 token 需要折腾一下。网上给出了几种方案,我使用的是用 Root 过的安卓手机。在手机上安装 5.0.19 版的米家(这是最后一个版本支持通过本地sqlite数据库查询 token 的版本),登陆米家,然后手机上打开文件管理器(比如ES文件管理器),把 /data/data/com.xiaomi.smarthome/databases/miio2.db 复制到电脑可访问的目录(比如SD卡),然后通过USB 把文件从手机转移到电脑上,用 sqlite 软件查询 devicerecord 表,其中有个 token 字段,那个就是了。
其他的一些Wifi设备参考这里:https://home-assistant.cc/component/xiaomi/wifi/
接入苹果HomeKit
配置这个的好处是,可以使用 Siri 来控制你的家庭智能场景和设备。
增加如下配置:
1 | homekit: |
保存重启服务后,会在主面板看到一个PIN码,这时候打开iPhone,找到 Home ,“添加配件”,“没有代码或无法扫描”,“输入代码”,把刚才的PIN码输入进去即可。
其他配置可参考这里:https://home-assistant.cc/homekit/builtin/
接入路由器
我的是网件路由刷的华硕的固件,因此找到华硕的配置如下:
1 | asuswrt: |
其他路由参考:https://home-assistant.cc/component/router/
自定义组件
有时候,有些设备可能自带的组件并不支持,那么需要去搜索安装下第三方组件,比如小米直流电风扇,就需要去下载 https://github.com/syssi/xiaomi_fan 到 config 目录下面,

然后按照第三方插件给的说明增加配置即可。
位置和天气设置
查询下经纬度,可以把经纬度设置好,之后就能显示当地的日落日出时间了。
1 | homeassistant: |
我使用的是yahoo天气的数据,配置如下:
1 | weather: |
其中 woeid 需要自己去 https://www.yahoo.com/news/weather/ 查询城市天气,URL中的id即为 woeid。
个性化设置
个性化设置在 “配置” -> “自定义” 里面,在这里可以修改每个接入设备的名字等参数,并且可以设置是否隐藏(这个还是挺有用的,尤其是接入了路由器的情况下,会有很多的 device_tracker 类的设备,都显示在面板上显然是很乱的)。
一些可以参考的参数:https://home-assistant.cc/system/customize/
智能语言
配置这个的目的是为了能通过语音合成技术进行结果输出(播报)。
直接参考这里即可: https://home-assistant.cc/component/nlp/
结语
基本的配置就这些,目前家里所有的智能设备都加入到了 Home Assistant 的管理中了,之后就是配置各种智能逻辑了,等我试验过后,会在下一篇写一下。
Over!